ML-Modelle schätzen den langfristigen Wert von Kunden und leiten Marketing-Investitionsentscheidungen.
Index

1. Einführung
Die Bedeutung des Customer Lifetime Value (CLV) für Ihr Unternehmen.
Im digitalen Zeitalter ist es entscheidend, die Profitabilität Ihrer Kunden zu verstehen und vorherzusagen. Der Customer Lifetime Value (CLV) ist eine Kennzahl, die Ihnen genau dies ermöglicht. Sie hilft Ihnen, den langfristigen Wert Ihrer Kunden zu ermitteln und fundierte Entscheidungen für Marketingstrategien, Kundenakquisitionskosten und Kundenbindungsmaßnahmen zu treffen. In dieser Fallstudie zeige ich, wie die Berechnung des CLV Ihr Unternehmen voranbringen kann.
Berechnung
CLV & CAC Formel lautet:
CLV=Durchschnittlicher Bestellwert × Kaufhäufigkeit× Kundenlebensdauer
Kundenakquisitionskosten (CAC):
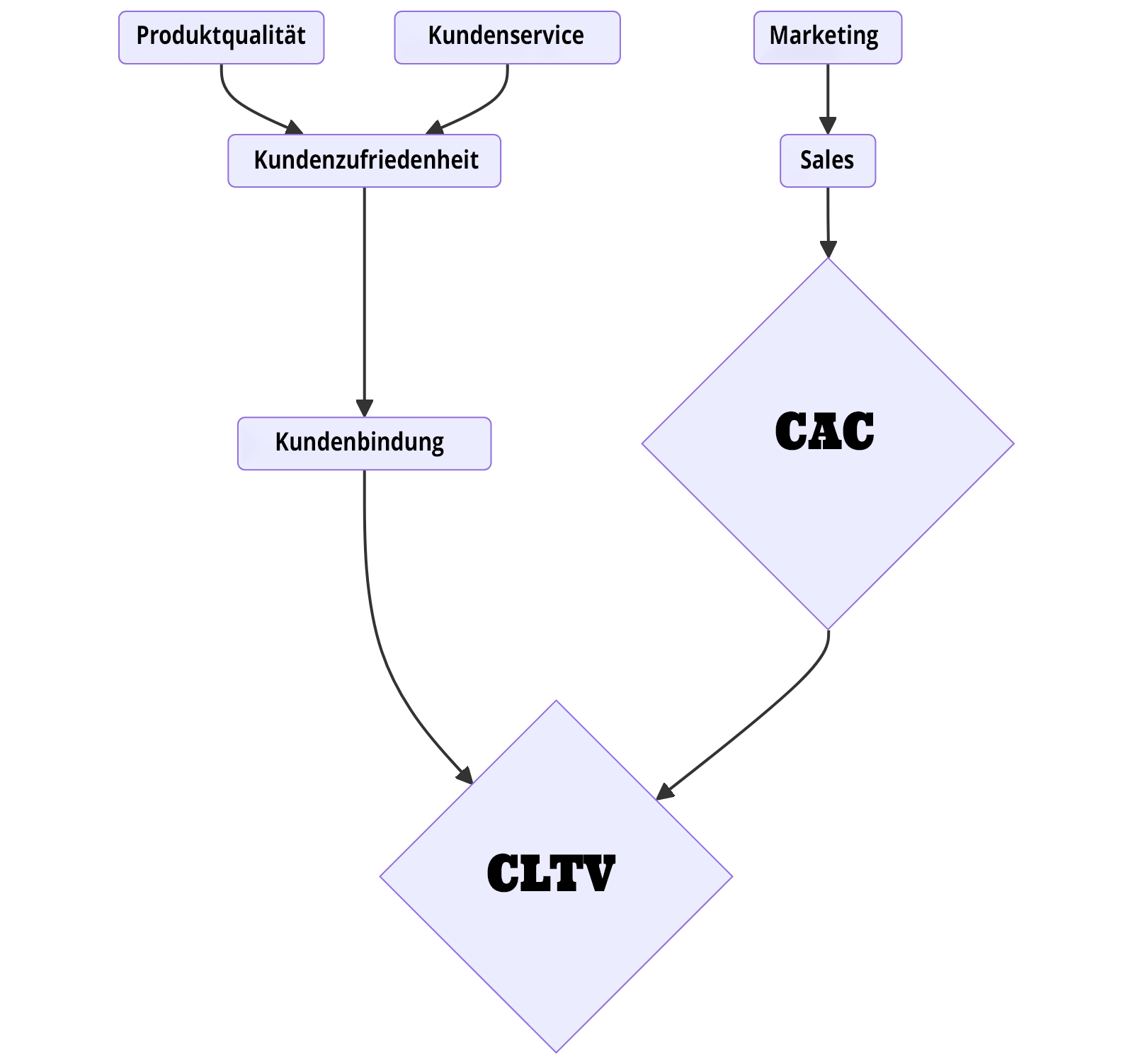
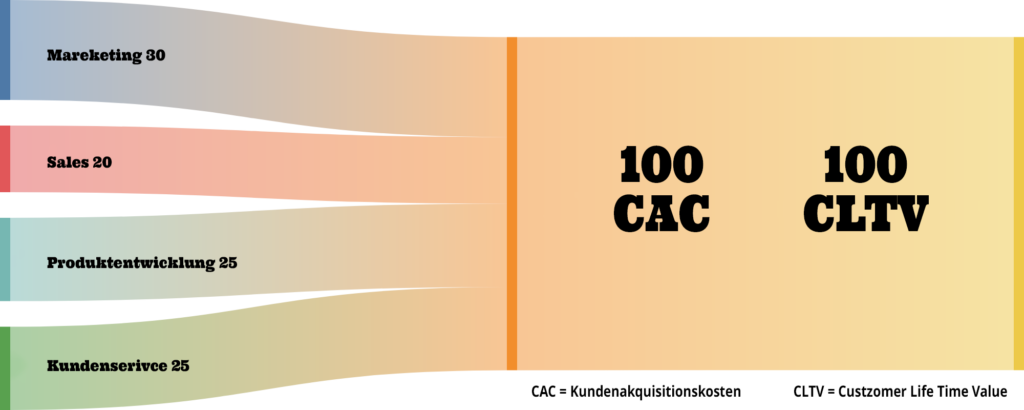
Die obige Grafik zeigt, wie verschiedene Kostenfaktoren zu den Kundenakquisitionskosten (CAC) beitragen und wie diese wiederum den Customer Lifetime Value (CLTV) beeinflussen.
Marketing (30)
Marketingkosten machen einen bedeutenden Teil der CAC aus. Investitionen in Marketingstrategien und -kampagnen sind notwendig, um potenzielle Kunden auf das Unternehmen aufmerksam zu machen und sie zur Conversion zu bewegen.
Sales (20)
Kosten für Vertriebspersonal und Verkaufsstrategien tragen ebenfalls zu den CAC bei. Diese Ausgaben sind wichtig, um potenzielle Kunden zu qualifizieren und sie durch den Verkaufstrichter zu führen.
Produktentwicklung (25):
Investitionen in die Produktentwicklung sind entscheidend, um Produkte zu schaffen, die den Bedürfnissen der Kunden entsprechen. Gute Produkte verbessern die Kundenzufriedenheit und tragen indirekt dazu bei, die CAC zu senken, indem sie die Conversion-Raten erhöhen.
Kundenservice (25)
Ein exzellenter Kundenservice ist entscheidend für die Kundenzufriedenheit und -bindung. Investitionen in den Kundenservice verbessern die Kundenbindung und erhöhen somit den CLTV.
2. Beschreibung des Datensatzes
Datensatz: Einblicke in das Kundenverhalten
Der Datensatz, den wir verwendet haben, stammt aus einer Online-Retail-Datenbank und umfasst Transaktionen von etwa 5000 Kunden. Er enthält Informationen über die Kaufhistorie, Produktdetails und Transaktionsbeträge. Mit diesen Daten haben wir den CLV für jeden Kunden berechnet und analysiert.
| Invoice | StockCode | Description | Quantity | InvoiceDate | Price | Customer ID | Country | TotalPrice |
|---|---|---|---|---|---|---|---|---|
| 489434 | 85048 | 15CM CHRISTMAS GLASS BALL 20 LIGHTS | 12 | 2009-12-01 07:45:00 | 6.95 | 13085.0 | United Kingdom | 83.4 |
| 489434 | 79323P | PINK CHERRY LIGHTS | 12 | 2009-12-01 07:45:00 | 6.75 | 13085.0 | United Kingdom | 81.0 |
| 489434 | 79323W | WHITE CHERRY LIGHTS | 12 | 2009-12-01 07:45:00 | 6.75 | 13085.0 | United Kingdom | 81.0 |
| 489434 | 22041 | RECORD FRAME 7″ SINGLE SIZE | 48 | 2009-12-01 07:45:00 | 2.10 | 13085.0 | United Kingdom | 100.8 |
| 489434 | 21232 | STRAWBERRY CERAMIC TRINKET BOX | 24 | 2009-12-01 07:45:00 | 1.25 | 13085.0 | United Kingdom | 30.0 |
| 489434 | 22064 | PINK DOUGHNUT TRINKET POT | 24 | 2009-12-01 07:45:00 | 1.65 | 13085.0 | United Kingdom | 39.6 |
| 489434 | 21871 | SAVE THE PLANET MUG | 24 | 2009-12-01 07:45:00 | 1.25 | 13085.0 | United Kingdom | 30.0 |
| 489434 | 21523 | FANCY FONT HOME SWEET HOME DOORMAT | 10 | 2009-12-01 07:45:00 | 5.95 | 13085.0 | United Kingdom | 59.5 |
| 489435 | 22350 | CAT BOWL | 12 | 2009-12-01 07:46:00 | 2.55 | 13085.0 | United Kingdom | 30.6 |
| 489435 | 22349 | DOG BOWL , CHASING BALL DESIGN | 12 | 2009-12-01 07:46:00 | 3.75 | 13085.0 | United Kingdom | 45.0 |
| Eigenschaft | Wert |
|---|---|
| Shape (Form) | (525461, 8) |
| Features | Invoice | StockCode | Description | Quantity | InvoiceDate | Price | Customer ID | Country |
|---|---|---|---|---|---|---|---|---|
| Datentyp | object | object | object | int64 | datetime64[ns] | float64 | float64 | object |
| Metrik | Anzahl (count) | Durchschnitt (mean) | Minimum (min) | 1% | 25% | 50% (Median) | 75% | 99% | Maximum (max) | Standardabweichung (std) |
|---|---|---|---|---|---|---|---|---|---|---|
| Quantity | 525461.0 | 8.685688 | -9600.0 | -3.0 | 1.0 | 3.0 | 10.0 | 120.0 | 304.5 | 60.954547 |
| InvoiceDate | 525461 | 2010-06-28 11:37:36.845017856 | 2009-12-01 07:45:00 | 2009-12-02 14:36:00 | 2010-03-09 14:25:00 | 2010-06-28 11:37:36.845017856 | 2010-10-15 12:45:00 | 2010-12-08 10:40:00 | 2010-12-09 20:01:00 | NaN |
| Price | 525461.0 | 3.26451 | -53594.36 | 0.21 | 1.25 | 2.08 | 4.21 | 19.95 | 49.56 | 109.822785 |
| Customer ID | 417534.0 | 15360.645478 | 12346.0 | 12435.0 | 13969.0 | 15311.0 | 16799.0 | 18196.0 | 18287.0 | 1680.811316 |
Anzahl der verkauften Einheiten. Negative Werte können auf Rücksendungen hinweisen.
Datum und Uhrzeit der Rechnungserstellung.
Preis pro Einheit. Negative Werte können auf Fehler oder Rückerstattungen hinweisen.
Eindeutige Kennung des Kunden.
3. Zielsetzung des Modells
Zielsetzung: Maximierung des Kundenwerts
Unser Ziel war es, ein Modell zu entwickeln, das den CLV für jeden Kunden genau vorhersagt. Dies ermöglicht es uns, wertvolle Kunden zu identifizieren und gezielte Marketingstrategien zu entwickeln, um den Umsatz und die Rentabilität zu steigern.
4. Methodik
Methodik, Von der Datenvorbereitung bis zur Modellierung
Ich habe den Datensatz gründlich bereinigt und vorbereitet, um sicherzustellen, dass die Daten für die Modellierung geeignet sind. Dies umfasste die Entfernung von Ausreißern, die Handhabung fehlender Werte und die Berechnung zusätzlicher Metriken wie `TotalPrice` und `Recency`.
Datenvorbereitung
Fehlende Werte
| Invoice | 0 |
| StockCode | 0 |
| Description | 2928 |
| Quantity | 0 |
| InvoiceDate | 0 |
| Price | 0 |
| Customer ID | 107927 |
| Country | 0 |
| Dies zeigt an, dass die Transaktionsaufzeichnungen vollständig sind. |
| Alle Artikel haben eine Artikelnummer, was eine ordnungsgemäße Identifizierung der Produkte gewährleistet. |
| Das Fehlen von Artikelbeschreibungen kann die detaillierte Analyse der Produktinformationen beeinträchtigen. |
| Stellt sicher, dass alle Transaktionen eine angegebene Menge haben, was für die Verkaufsanalyse entscheidend ist. |
| Alle Transaktionen haben ein Datum und eine Uhrzeit, was eine genaue Zeitreihenanalyse ermöglicht. |
| Alle Transaktionen haben einen Preis, was für die Umsatzberechnungen unerlässlich ist. |
| Das Fehlen von Kunden-IDs kann die Kundensegmentierung und personalisierte Marketingbemühungen beeinträchtigen. |
| Stellt sicher, dass alle Transaktionen ein angegebenes Land haben, was für geografische Analysen nützlich ist. |
Quantile Tabelle
| 0.00 | 0.05 | 0.50 | 0.75 | 0.95 | 1.00 | ||
|---|---|---|---|---|---|---|---|
| Menge | -9600.00 | 1.00 | 3.0 | 10.00 | 30.00 | 19152.00 | Zeigt die Verteilung der Menge von Artikeln in Transaktionen an. Negative Werte könnten Rückgaben darstellen. |
| Preis | -53594.36 | 0.42 | 2.1 | 4.21 | 10.17 | 25111.09 | Zeigt die Preisverteilung der Artikel. Negative Preise könnten auf Fehler oder spezielle Anpassungen hinweisen. |
| Kunden-ID | 12346.00 | 12725.00 | 15311.0 | 16799.00 | 17913.00 | 18287.00 | Zeigt die Verteilung der Kunden-IDs, was nützlich ist, um die Kundenbasis zu verstehen. |
| Einzigartige Kunden | 4383 | Gesamtanzahl der einzigartigen Kunden in den Daten. | |||||
Ausreißer Entfernen
Datenvorbereitung und Kundensegmentierung zur Berechnung des Customer Lifetime Value (CLV)
Das Ziel der Datenvorbereitung ist es, ein umfassendes Verständnis der Kaufhistorie und des Kaufverhaltens unserer Kunden zu gewinnen. Dies umfasst:
Identifikation von Transaktionsmustern: Erkennen, wie oft Kunden einkaufen und welche Artikel sie bevorzugen.
Berechnung des CLV: Nutzung von Modellen wie BG-NBD (Beta-Geometric/Negative Binomial Distribution) und Gamma-Gamma-Modellen, um den zukünftigen Wert eines Kunden auf Basis vergangener Transaktionen vorherzusagen.
Segmentierung der Kunden: Einteilung der Kunden in verschiedene Segmente basierend auf ihrem CLV, um gezielte Marketingstrategien zu entwickeln.
| Invoice | StockCode | Description | Quantity | InvoiceDate | Price | Customer ID | Country | TotalPrice | Year | Month | Day | DayOfWeek |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 489434 | 85048 | 15CM CHRISTMAS GLASS BALL 20 LIGHTS | 12.0 | 2009-12-01 07:45:00 | 6.95 | 13085.0 | United Kingdom | 83.4 | 2009 | 12 | 1 | 1 |
| 489434 | 79323P | PINK CHERRY LIGHTS | 12.0 | 2009-12-01 07:45:00 | 6.75 | 13085.0 | United Kingdom | 81.0 | 2009 | 12 | 1 | 1 |
| 489434 | 79323W | WHITE CHERRY LIGHTS | 12.0 | 2009-12-01 07:45:00 | 6.75 | 13085.0 | United Kingdom | 81.0 | 2009 | 12 | 1 | 1 |
| 489434 | 22041 | RECORD FRAME 7″ SINGLE SIZE | 48.0 | 2009-12-01 07:45:00 | 2.10 | 13085.0 | United Kingdom | 100.8 | 2009 | 12 | 1 | 1 |
| 489434 | 21232 | STRAWBERRY CERAMIC TRINKET BOX | 24.0 | 2009-12-01 07:45:00 | 1.25 | 13085.0 | United Kingdom | 30.0 | 2009 | 12 | 1 | 1 |
Überblick über den Datensatz
Der Datensatz umfasst 417.534 Beobachtungen und 13 Variablen. Diese Daten wurden sorgfältig analysiert und in verschiedene Kategorien unterteilt, um tiefere Einblicke zu gewinnen und die Kundenwertanalyse (Customer Lifetime Value, CLV) zu unterstützen.
Observations: 417534
Variables: 13
cat_cols: 3
num_cols: 6
cat_but_car: 4
num_but_cat: 2
Kategorische Spalten: ['Customer Segment', 'Year', 'DayOfWeek']
Numerische Spalten: ['Quantity', 'InvoiceDate', 'Price', 'Customer ID', 'Month', 'Day']
Cardinale Spalten: ['Invoice', 'StockCode', 'Description', 'Country']
Numerisch aber kategorisch: ['Year', 'DayOfWeek']
2010-12-09 20:01:00
2009-12-01 07:45:00Weitere Details zu Kategorien der Variablen:
- Kategorische Spalten (cat_cols):
- Customer Segment: Segmentierung der Kunden basierend auf ihrem Wert.
- Year: Das Jahr der Transaktion.
- DayOfWeek: Der Wochentag der Transaktion.
- Numerische Spalten (num_cols):
- Quantity: Die Anzahl der gekauften Artikel.
- InvoiceDate: Das Datum der Transaktion.
- Price: Der Preis pro Artikel.
- Customer ID: Die eindeutige Kundenidentifikationsnummer.
- Month: Der Monat der Transaktion.
- Day: Der Tag der Transaktion.
- Cardinale Spalten (cat_but_car):
- Invoice: Die Rechnungsnummer.
- StockCode: Der Artikelcode.
- Description: Die Beschreibung des Artikels.
- Country: Das Land, in dem die Transaktion stattfand.
Weitere Details zur Datenstruktur
- Numerisch aber kategorisch (num_but_cat):
- Year: Das Jahr wird zwar numerisch dargestellt, hat aber eine begrenzte Anzahl an eindeutigen Werten.
- DayOfWeek: Der Wochentag, ebenfalls numerisch, jedoch mit einer begrenzten Anzahl an Werten (1-7).
Zeitrahmen der Daten
- Aktuellstes Transaktionsdatum: 2010-12-09 20:01:00
- Ältestes Transaktionsdatum: 2009-12-01 07:45:00
Übersicht der Kundensegmentierung
Die Kundensegmentierung basiert auf dem berechneten CLV und teilt die Kunden in verschiedene Kategorien ein. Dies ermöglicht eine gezielte Ansprache und eine effiziente Nutzung der Marketingressourcen.
Customer ID Customer Segment
0 13085.0 Mid-Value
12 13078.0 High-Value
31 15362.0 Mid-Value
54 18102.0 High-Value
71 12682.0 High-ValueFeature Engineering
Erstellung des CLTV-Datensatzes
in DataFrame (cltv_df) wird erstellt, der die notwendigen Kennzahlen für das Modell enthält: recency, T, frequency und monetary_value.
# Erstellen von cltv_df
today_date = df['InvoiceDate'].max() + pd.Timedelta(days=1)
cltv_df = df.groupby('Customer ID').agg({
'InvoiceDate': [
lambda x: (x.max() - x.min()).days,
lambda x: (today_date - x.min()).days
],
'Invoice': 'nunique',
'TotalPrice': 'sum'
})
cltv_df.columns = ['recency', 'T', 'frequency', 'monetary_value']
cltv_df['monetary_value'] = cltv_df['monetary_value'] / cltv_df['frequency']
cltv_df = cltv_df[(cltv_df['frequency'] > 1) & (cltv_df['monetary_value'] > 0)]
cltv_df['recency'] = cltv_df['recency'] / 7
cltv_df['T'] = cltv_df['T'] / 7Recency: Zeitspanne zwischen dem ersten und dem letzten Kauf.
T: Zeitspanne vom ersten Kauf bis zum Analysezeitpunkt.
Frequency: Anzahl der Einkäufe.
Monetary Value: Durchschnittlicher Transaktionswert.
recency T frequency monetary_value
Customer ID
12346.0 28.000000 51.571429 11 33.896364
12347.0 5.285714 5.714286 2 661.660000
12349.0 25.857143 32.142857 3 890.380000
12352.0 2.285714 4.000000 2 171.900000
12356.0 6.285714 8.571429 3 1187.416667Modellerstellung und Bewertung
Die Daten werden in Trainings- und Testdatensätze aufgeteilt. Das BG/NBD-Modell und das Gamma-Gamma-Modell werden erstellt, um den CLV vorherzusagen.
BG-NBD (Beta-Geometric/Negative Binomial Distribution) Modell
Modellinitialisierung und Anpassung:
# Split in Trainings- und Testdaten
train, test = train_test_split(cltv_df, test_size=0.2, random_state=42)
# BG/NBD-Modell
bgf = BetaGeoFitter(penalizer_coef=0.001)
bgf.fit(train['frequency'], train['recency'], train['T'])
# Gamma-Gamma-Modell
ggf = GammaGammaFitter(penalizer_coef=0.01)
ggf.fit(train['frequency'], train['monetary_value'])
# CLV-Vorhersage
train['predicted_clv'] = ggf.customer_lifetime_value(
bgf,
train['frequency'],
train['recency'],
train['T'],
train['monetary_value'],
time=6,
freq='W',
discount_rate=0.01
)
test['predicted_clv'] = ggf.customer_lifetime_value(
bgf,
test['frequency'],
test['recency'],
test['T'],
test['monetary_value'],
time=6,
freq='W',
discount_rate=0.01
)
# Modellbewertung
def evaluate_model(actual, predicted):
rmse = np.sqrt(mean_squared_error(actual, predicted))
mae = mean_absolute_error(actual, predicted)
r2 = r2_score(actual, predicted)
print(f'RMSE: {rmse}')
print(f'MAE: {mae}')
print(f'R^2: {r2}')
evaluate_model(test['monetary_value'] * test['frequency'], test['predicted_clv'])
RMSE: 9687.49976096235
MAE: 1793.7058314731114
R^2: 0.6243720057132962Das BG-NBD Modell wird initialisiert und an die Daten angepasst.
Es nutzt die Kaufhäufigkeit (frequency), die Zeit seit dem letzten Kauf (recency) und die Kundenlebensdauer (T).
Optimierung des BG/NBD-Modells
Hyperparameter für das BG/NBD-Modell werden optimiert, um die Genauigkeit zu verbessern.
# Manuelle Hyperparameter-Optimierung für BG/NBD-Modell
penalizer_coefs = [0.001, 0.01, 0.1, 1]
best_rmse = float('inf')
best_coef = None
for coef in penalizer_coefs:
bgf = BetaGeoFitter(penalizer_coef=coef)
bgf.fit(train['frequency'], train['recency'], train['T'])
test['predicted_clv'] = ggf.customer_lifetime_value(
bgf,
test['frequency'],
test['recency'],
test['T'],
test['monetary_value'],
time=6,
freq='W',
discount_rate=0.01
)
rmse = np.sqrt(mean_squared_error(test['monetary_value'] * test['frequency'], test['predicted_clv']))
print(f'Penalizer Coef: {coef}, RMSE: {rmse}')
if rmse < best_rmse:
best_rmse = rmse
best_coef = coef
print(f'Best Penalizer Coef: {best_coef}, Best RMSE: {best_rmse}')
Best Penalizer Coef: 1, Best RMSE: 9046.908875797037Optimiertes Modell und Bewertung
Das optimierte BG/NBD-Modell wird verwendet, um die CLV-Vorhersagen zu verbessern. Eine ähnliche Optimierung wird für das Gamma-Gamma-Modell durchgeführt.
# Optimiertes Modell mit besten Parametern
bgf_optimized = BetaGeoFitter(penalizer_coef=best_coef)
bgf_optimized.fit(train['frequency'], train['recency'], train['T'])
# CLV-Vorhersage mit optimiertem Modell
train['optimized_predicted_clv'] = ggf.customer_lifetime_value(
bgf_optimized,
train['frequency'],
train['recency'],
train['T'],
train['monetary_value'],
time=6,
freq='W',
discount_rate=0.01
)
test['optimized_predicted_clv'] = ggf.customer_lifetime_value(
bgf_optimized,
test['frequency'],
test['recency'],
test['T'],
test['monetary_value'],
time=6,
freq='W',
discount_rate=0.01
)
# Bewertung des optimierten Modells
evaluate_model(test['monetary_value'] * test['frequency'], test['optimized_predicted_clv'])
# Visualisierung der Ergebnisse
plt.figure(figsize=(10, 6))
sns.scatterplot(x=test['monetary_value'] * test['frequency'], y=test['optimized_predicted_clv'], alpha=0.5)
plt.plot([test['monetary_value'].min() * test['frequency'].min(), test['monetary_value'].max() * test['frequency'].max()],
[test['monetary_value'].min() * test['frequency'].min(), test['optimized_predicted_clv'].max()], 'r--', linewidth=2)
plt.title('Tatsächlicher CLV vs. Prädiktiver CLV mit optimiertem Modell')
plt.xlabel('Tatsächlicher CLV')
plt.ylabel('Prädiktiver CLV')
plt.show()
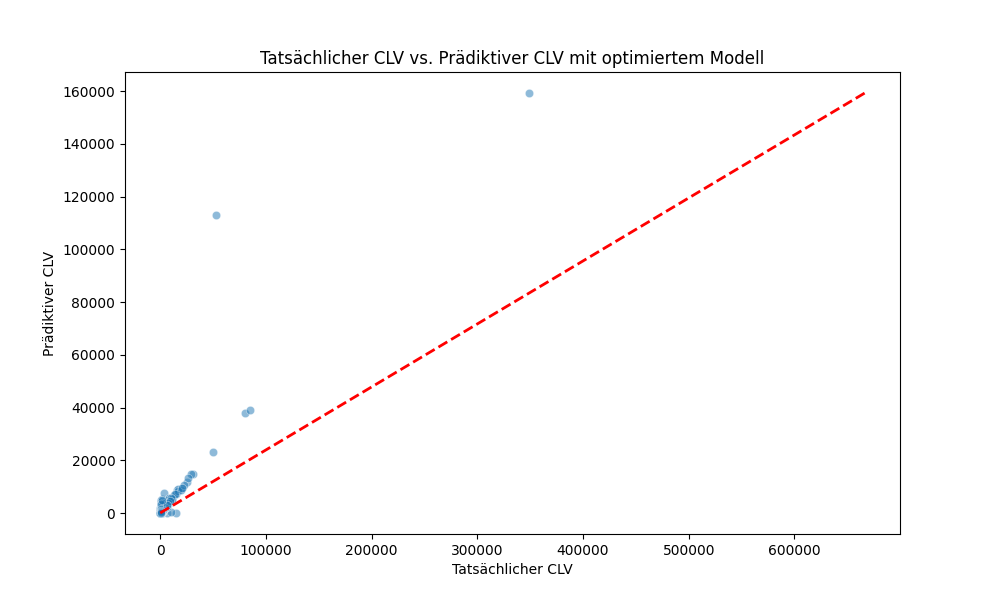
Details
Der Graph zeigt den Vergleich zwischen dem tatsächlichen Customer Lifetime Value (CLV) und dem prädiktiven CLV, der durch das optimierte Modell berechnet wurde. Auf der x-Achse befindet sich der tatsächliche CLV, während die y-Achse den prädiktiven CLV darstellt. Die rote gestrichelte Linie repräsentiert die Linie, auf der die prädiktiven Werte den tatsächlichen Werten exakt entsprechen würden (Ideal- oder Diagonallinie).
Wichtige Beobachtungen:
- Konvergenz zur Ideal-Linie: Ein Großteil der Punkte liegt nahe an der Ideal-Linie, was darauf hinweist, dass das Modell in vielen Fällen sehr genaue Vorhersagen trifft.
- Ausreißer: Es gibt einige Punkte, die weit von der Ideal-Linie entfernt sind. Diese Ausreißer zeigen, dass das Modell in einigen Fällen den tatsächlichen CLV nicht genau vorhersagen konnte. Dies könnte auf außergewöhnliche Kundenverhalten oder unzureichende Daten zurückzuführen sein.
- Verteilung der Daten: Die meisten Datenpunkte befinden sich im unteren linken Bereich des Diagramms, was darauf hinweist, dass die meisten Kunden einen relativ niedrigen CLV haben. Dies ist ein typisches Muster in vielen Geschäftsmodellen, wo eine kleine Anzahl von Kunden einen hohen CLV hat.
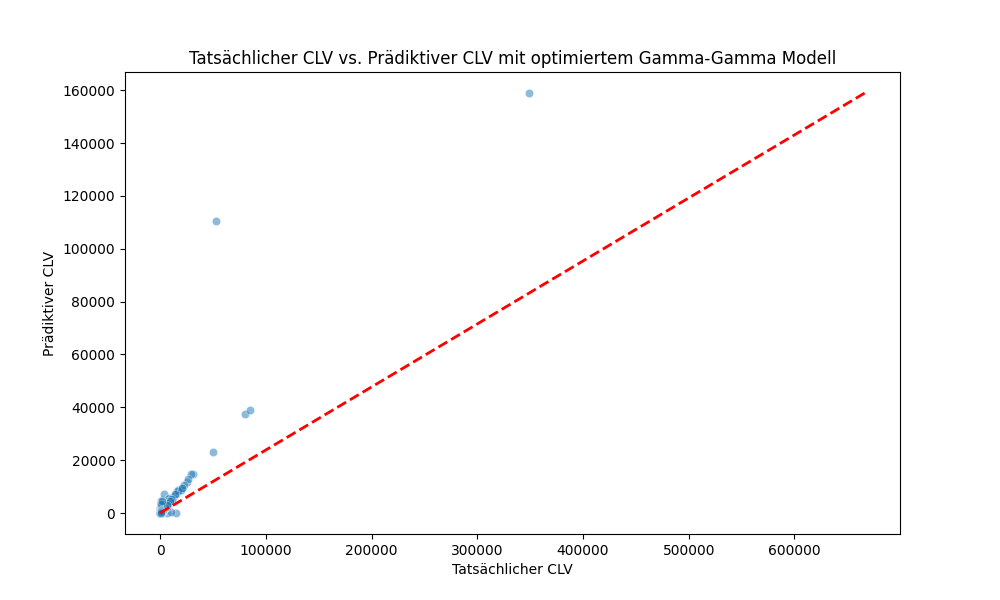
Details
Der Graph zeigt den Vergleich zwischen dem tatsächlichen Customer Lifetime Value (CLV) und dem prädiktiven CLV, der durch das optimierte Gamma-Gamma Modell berechnet wurde. Auf der x-Achse befindet sich der tatsächliche CLV, während die y-Achse den prädiktiven CLV darstellt. Die rote gestrichelte Linie repräsentiert die Linie, auf der die prädiktiven Werte den tatsächlichen Werten exakt entsprechen würden (Ideal- oder Diagonallinie).
Wichtige Beobachtungen:
- Konvergenz zur Ideal-Linie: Ein Großteil der Punkte liegt nahe an der Ideal-Linie, was darauf hinweist, dass das Modell in vielen Fällen sehr genaue Vorhersagen trifft.
- Ausreißer: Es gibt einige Punkte, die weit von der Ideal-Linie entfernt sind. Diese Ausreißer zeigen, dass das Modell in einigen Fällen den tatsächlichen CLV nicht genau vorhersagen konnte. Dies könnte auf außergewöhnliche Kundenverhalten oder unzureichende Daten zurückzuführen sein.
- Verteilung der Daten: Die meisten Datenpunkte befinden sich im unteren linken Bereich des Diagramms, was darauf hinweist, dass die meisten Kunden einen relativ niedrigen CLV haben. Dies ist ein typisches Muster in vielen Geschäftsmodellen, wo eine kleine Anzahl von Kunden einen hohen CLV hat.
Visualisierung der periodischen Transaktionen:
# Visualisierung der Frequenz von Wiederholungstransaktionen
def plot_repeat_transactions(bgf):
plt.figure(figsize=(10, 6))
plot_period_transactions(bgf)
plt.title('Frequency of Repeat Transactions')
plt.xlabel('Number of Calibration Period Transactions')
plt.ylabel('Customers')
plt.legend(['Actual', 'Model'])
plt.show()
plot_repeat_transactions(bgf)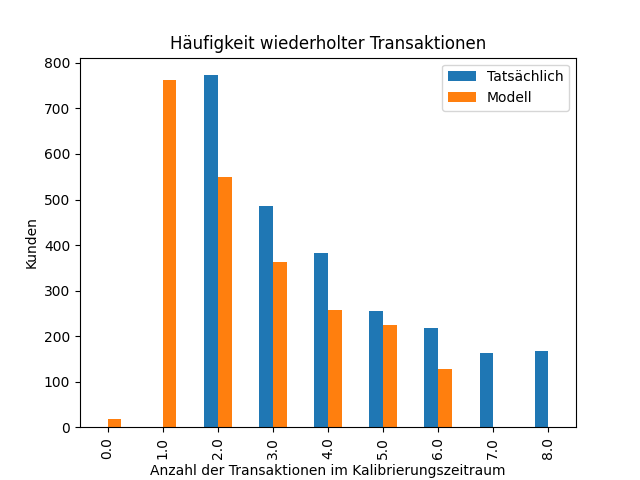
5. Ergebnisse
Visualisierungen
Ergebnisse: Einblicke in den Customer Lifetime Value
Unsere Analyse ergab, dass die meisten Kunden einen moderaten CLV haben, während eine kleine Gruppe von Kunden einen sehr hohen CLV aufweist. Diese Erkenntnisse halfen uns, gezielte Marketingmaßnahmen zu entwickeln.
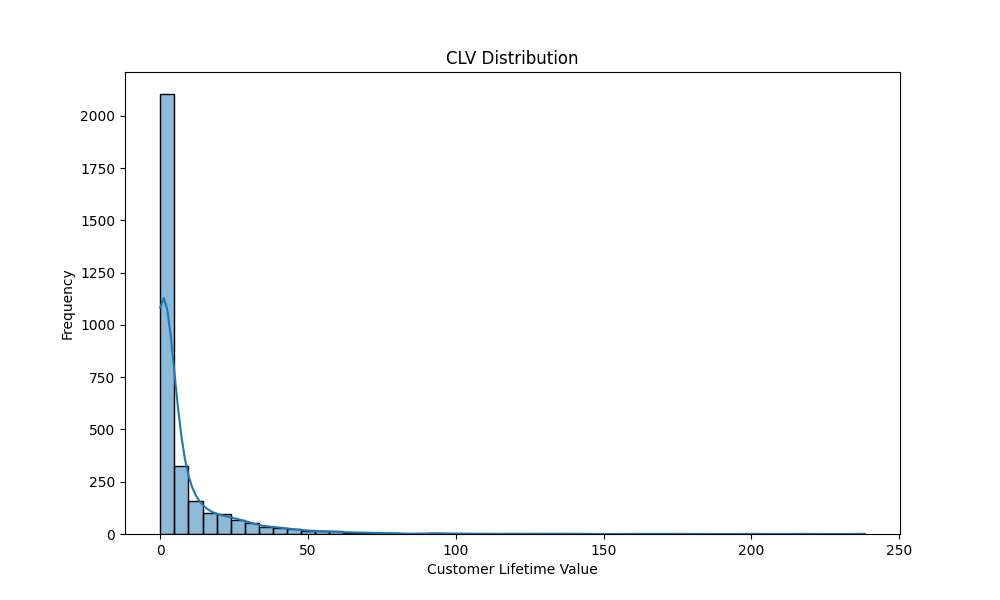
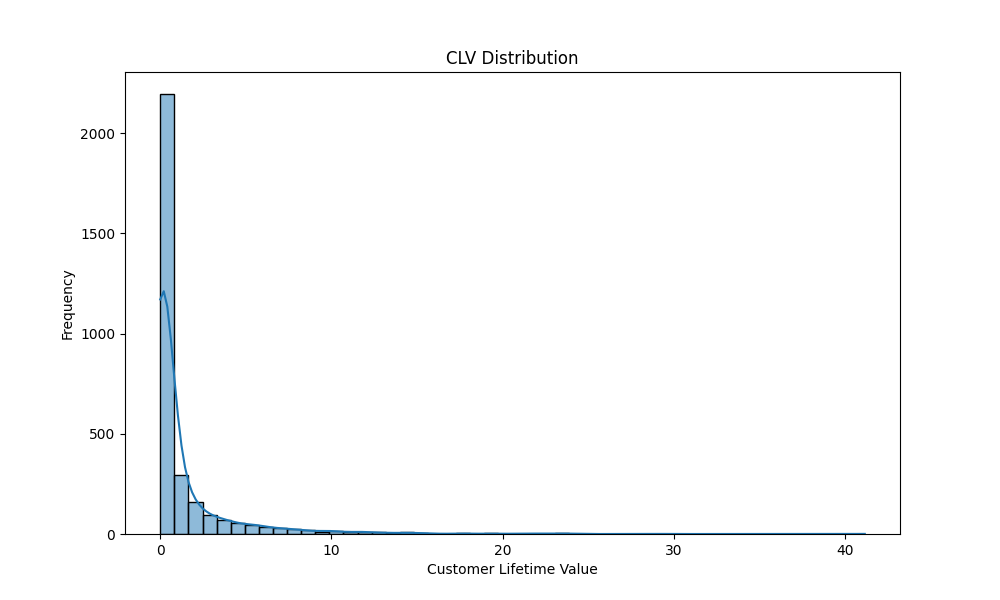
Das dargestellte Diagramm zeigt die Verteilung des Customer Lifetime Value (CLV) für die analysierten Kunden. Hier sind die wesentlichen Merkmale des Diagramms:
Details
Achsenbeschriftung:
- Die x-Achse repräsentiert den Customer Lifetime Value (CLV), also den geschätzten Gesamtwert, den ein Kunde während seiner gesamten Geschäftsbeziehung generieren wird.
- Die y-Achse zeigt die Häufigkeit der Kunden mit einem bestimmten CLV.
Verteilung:
- Das Histogramm weist eine stark rechtsschiefe Verteilung auf, was bedeutet, dass die Mehrheit der Kunden einen sehr niedrigen CLV hat.
- Ein großer Peak befindet sich bei einem CLV nahe null, was darauf hinweist, dass viele Kunden nur geringe Umsätze generieren.
- Der CLV-Wert fällt schnell ab, und nur wenige Kunden erreichen hohe CLV-Werte.
Häufigkeit:
- Die Häufigkeit der Kunden mit niedrigen CLV-Werten ist extrem hoch, während die Anzahl der Kunden mit hohen CLV-Werten sehr gering ist.
Niedrige CLV-Werte: Die meisten Kunden generieren nur geringe Umsätze und haben einen niedrigen CLV. Diese Kunden könnten Gelegenheitskäufer oder Kunden mit niedriger Kaufhäufigkeit sein.
Hohe CLV-Werte: Eine kleine Anzahl von Kunden zeigt einen sehr hohen CLV. Diese Kunden sind wertvoll für das Unternehmen, da sie häufiger kaufen und höhere Umsätze generieren.
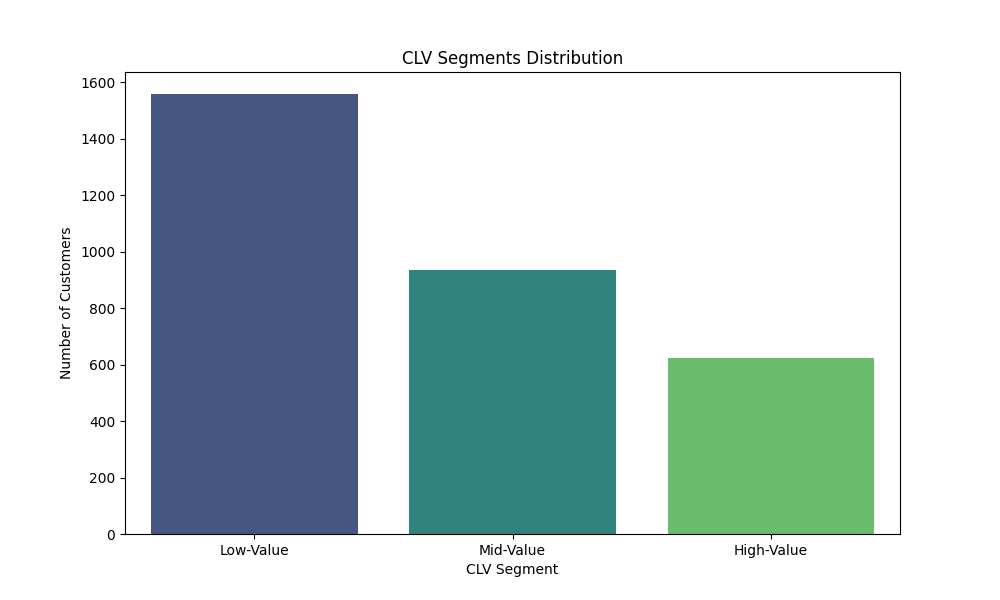
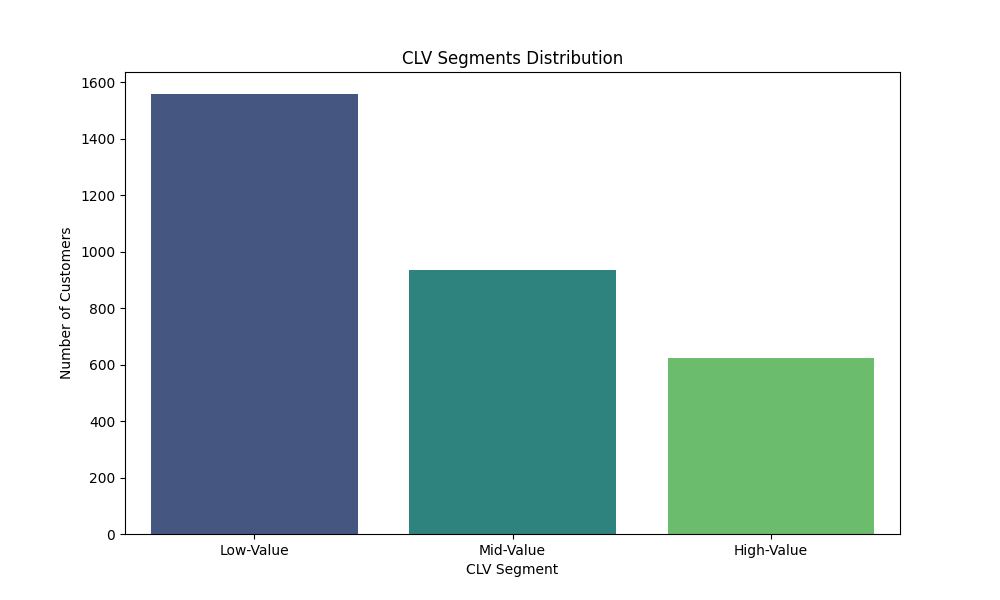
Das dargestellte Diagramm zeigt die Verteilung der Kunden in verschiedene Customer Lifetime Value (CLV)-Segmente. Hier sind die wesentlichen Merkmale des Diagramms:
Details
Achsenbeschriftung:
- Die x-Achse repräsentiert die CLV-Segmente: “Low-Value”, “Mid-Value” und “High-Value”.
- Die y-Achse zeigt die Anzahl der Kunden in den jeweiligen Segmenten.
Verteilung der Segmente:
- Low-Value: Die Mehrheit der Kunden fällt in das “Low-Value”-Segment. Diese Kunden generieren vergleichsweise niedrige Umsätze.
- Mid-Value: Eine moderate Anzahl von Kunden befindet sich im “Mid-Value”-Segment. Diese Kunden haben einen mittleren CLV.
- High-Value: Eine kleinere Gruppe von Kunden gehört zum “High-Value”-Segment. Diese Kunden sind besonders wertvoll, da sie hohe Umsätze generieren.
Häufigkeit:
Das “Low-Value”-Segment hat die höchste Anzahl von Kunden, was darauf hinweist, dass viele Kunden nur geringe Umsätze generieren.
Das “Mid-Value”-Segment hat eine mittlere Anzahl von Kunden.
Das “High-Value”-Segment hat die geringste Anzahl von Kunden, was auf eine kleine, aber sehr wertvolle Kundengruppe hinweist.
| Metric | expected_purc_4_weeks | expected_average_profit | clv |
|---|---|---|---|
| count | 3.116000e+03 | 3116.000000 | 3.116000e+03 |
| mean | 3.448278e-03 | 390.639800 | 8.184265e+00 |
| std | 5.715030e-03 | 422.139651 | 1.850674e+01 |
| min | 5.370700e-72 | 0.175926 | 1.487750e-68 |
| 25% | 8.496048e-05 | 195.655198 | 1.106731e-01 |
| 50% | 7.399354e-04 | 291.925299 | 1.294129e+00 |
| 75% | 4.276023e-03 | 452.547925 | 7.462548e+00 |
| max | 3.410675e-02 | 9669.412629 | 2.471568e+02 |
Schlussfolgerungen:
Fokus auf High-Value-Kunden: Das Unternehmen sollte Maßnahmen ergreifen, um diese wertvollen Kunden zu halten und deren Loyalität zu fördern. Personalisierte Angebote, Treueprogramme und gezieltes Marketing könnten hier besonders effektiv sein.
Verbesserung der Kundenbindung: Strategien sollten entwickelt werden, um Kunden aus den “Low-Value”- und “Mid-Value”-Segmenten zu fördern und zu höheren Umsätzen zu bewegen.
Regelmäßige Analyse und Anpassung: Die Segmentierung sollte regelmäßig überprüft und angepasst werden, um neue Trends zu erkennen und die Marketingstrategien entsprechend anzupassen.
6. Maßnahmen zur CLV-Verbesserung
Basierend auf unseren Ergebnissen empfehlen wir gezielte Maßnahmen zur Kundenbindung und -gewinnung. Für Kunden mit hohem CLV sollten exklusive Angebote und personalisierte Marketingstrategien entwickelt werden, während für Kunden mit niedrigem CLV Maßnahmen zur Steigerung des Engagements und zur Umsatzsteigerung ergriffen werden sollten.
7. Zusammenfassung
Ihr Weg zu höheren Umsätzen
Die Berechnung des CLV bietet wertvolle Einblicke in das Kundenverhalten und ermöglicht es Ihnen, gezielte Maßnahmen zur Steigerung der Kundenprofitabilität zu ergreifen. Nutzen Sie diese Erkenntnisse, um Ihr Geschäft nachhaltig zu wachsen.
Erfahren Sie mehr über die Vorteile der CLV-Berechnung
Möchten Sie mehr darüber erfahren, wie die Berechnung des CLV Ihr Unternehmen voranbringen kann? Kontaktieren Sie mich noch heute und entdecken Sie die Vorteile einer datengestützten Marketingstrategie.


Fordern Sie Ihr individuelles Angebot an.
EINFACH & UNVERBINDLICH
Füllen Sie unser Formular aus, und wir senden Ihnen umgehend ein maßgeschneidertes Angebot.